Modeling Pipeline
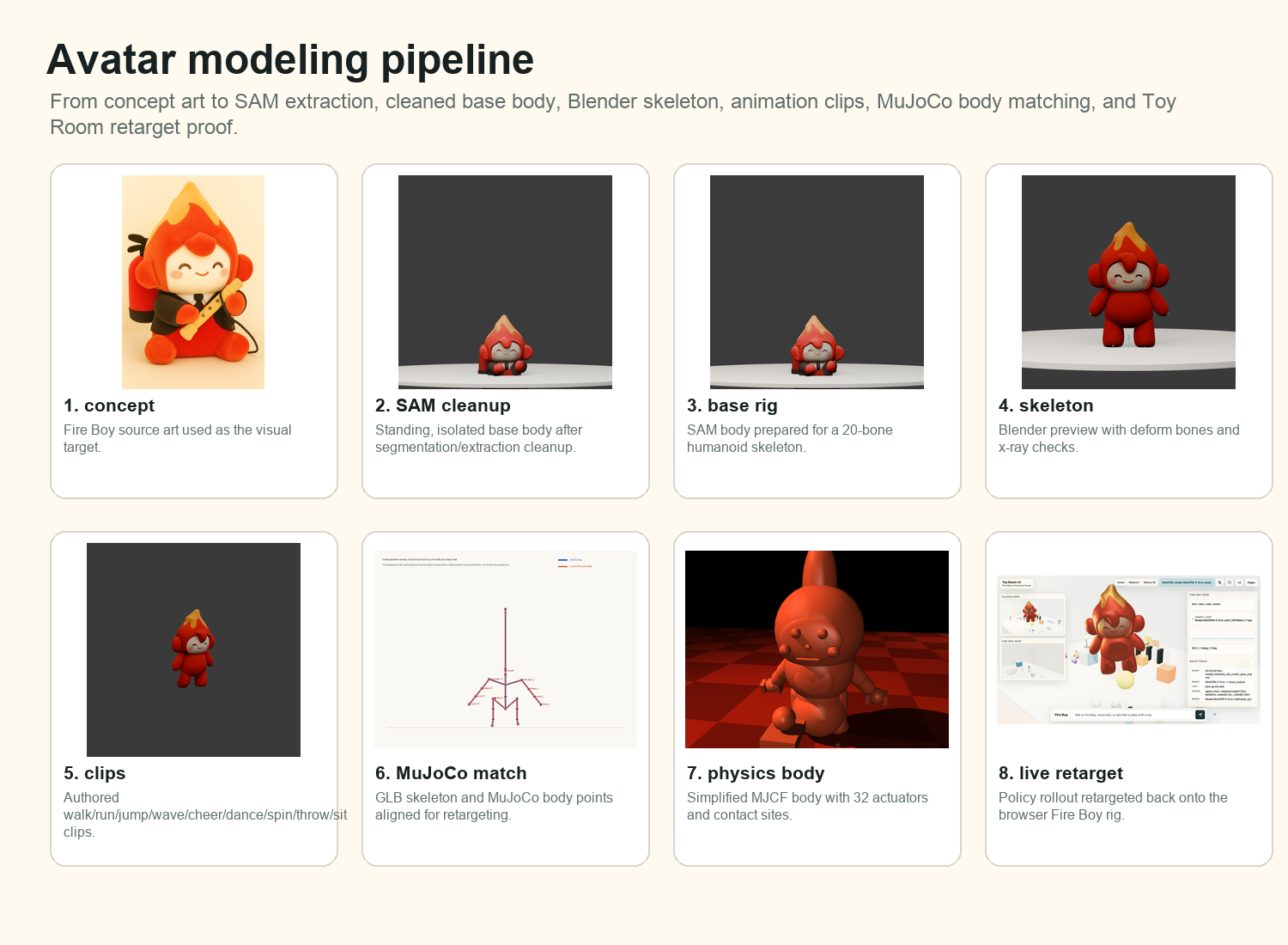
Fire Boy starts as concept art, moves through SAM-style extraction and cleanup, becomes a 20-bone Blender GLB, is matched to a MuJoCo body, and finally returns to the browser as retargeted Toy Room motion.
This page packages the training story into a judge-ready research artifact: how the MiniCPM-V backbone was frozen, how the router was added, which action-head experiments failed, which ones survived closed-loop physics, where Modal and RunPod fit, and how Codex helped scaffold the whole experimental loop.
This project came from an earlier attempt to build a real robot. The practical pivot was to build the thing that felt most alive first: a virtual toy, somewhere between Talking Tom, Tamagotchi, and an imaginary Pokémon-like companion, but updated for multimodal AI, physics, memory, and learned action. The goal is not just a chatbot with a mascot. The goal is a small creature that sees its room, understands commands, forms habits, chooses actions, plays with objects, reacts physically, and slowly develops a recognizable personality.
The hackathon build is the tiny version of that thesis. Fire Boy can be commanded, routed through a learned MiniCPM-V policy layer, retargeted into a rigged body, and shown with proof videos and debug traces. The future version is a full-stack pet brain: perception, memory, personality, physics rollouts, skill learning, reflex control, and a slow deliberative model working together.
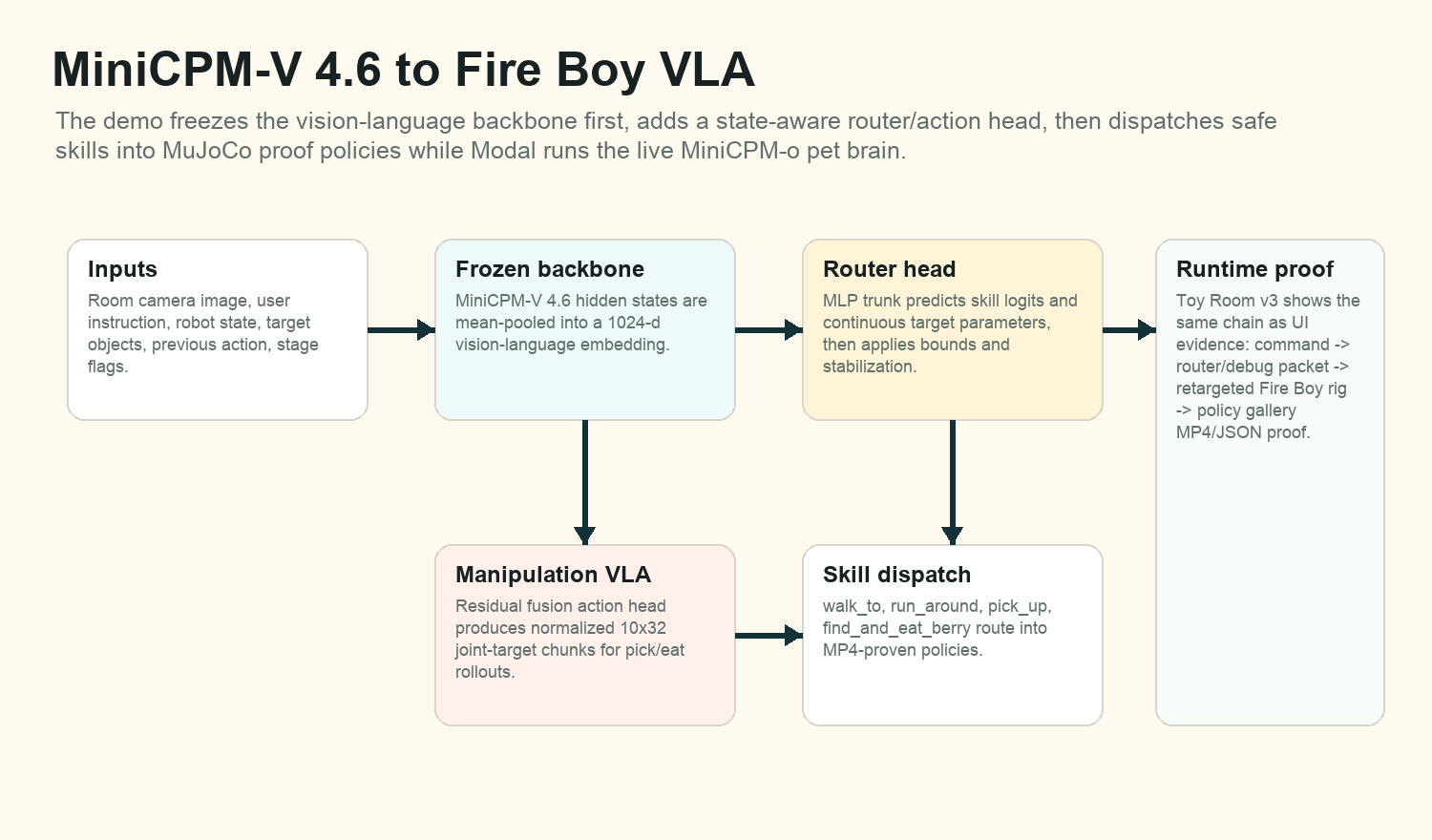
MiniCPM-V 4.6 already supplies image-language understanding, but Fire Boy needs actions: walk to a target, run around, pick up an object, eat a berry, and retarget proof trajectories onto a rigged Three.js body. The conversion freezes the MiniCPM-V backbone first, extracts a 1024-dimensional vision-language embedding, concatenates a robot-state vector, and trains small heads around that representation. The public demo promotes the skill-parameter router because it proved more reliable than a single monolithic low-level controller.
The router reads camera/image context, the user instruction, root pose, hand and mouth positions, target positions, task flags, stage flags, previous action, and grasp/eaten state. That state vector matters because the image alone does not expose velocities, contact phase, prior action, or whether an object is already held.
The final router predicts one of four skills plus six parameters: target_x, target_y, target_z, radius, speed_hint, and object_is_berry. Bounds and stabilizers keep those outputs in safe scene ranges before dispatching to policy registry skills.
Fire Boy starts as concept art, moves through SAM-style extraction and cleanup, becomes a 20-bone Blender GLB, is matched to a MuJoCo body, and finally returns to the browser as retargeted Toy Room motion.
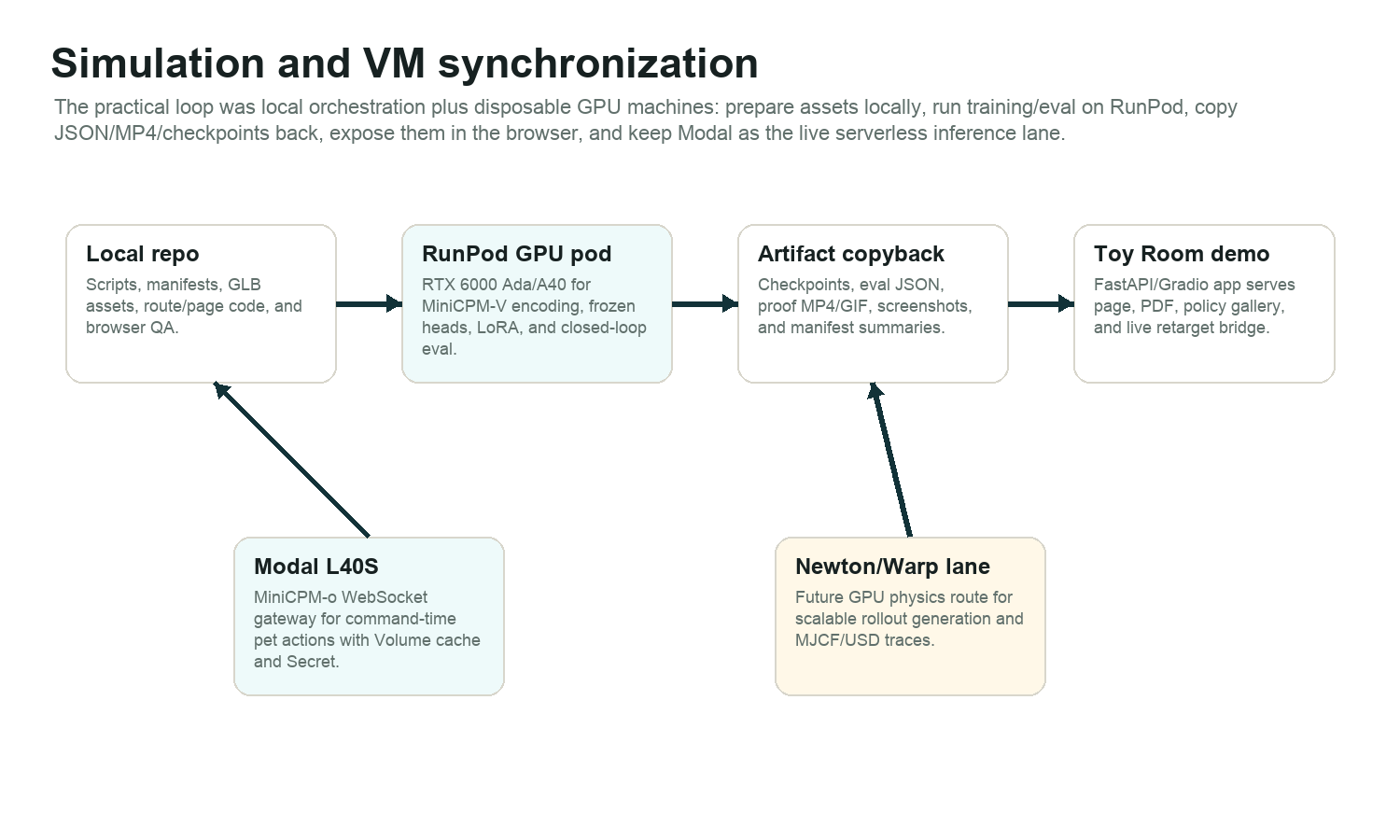
The practical research loop was local orchestration, RunPod GPU training/eval, artifact copyback, Modal serverless inference, and a documented Newton/Warp lane for future GPU rollout throughput.
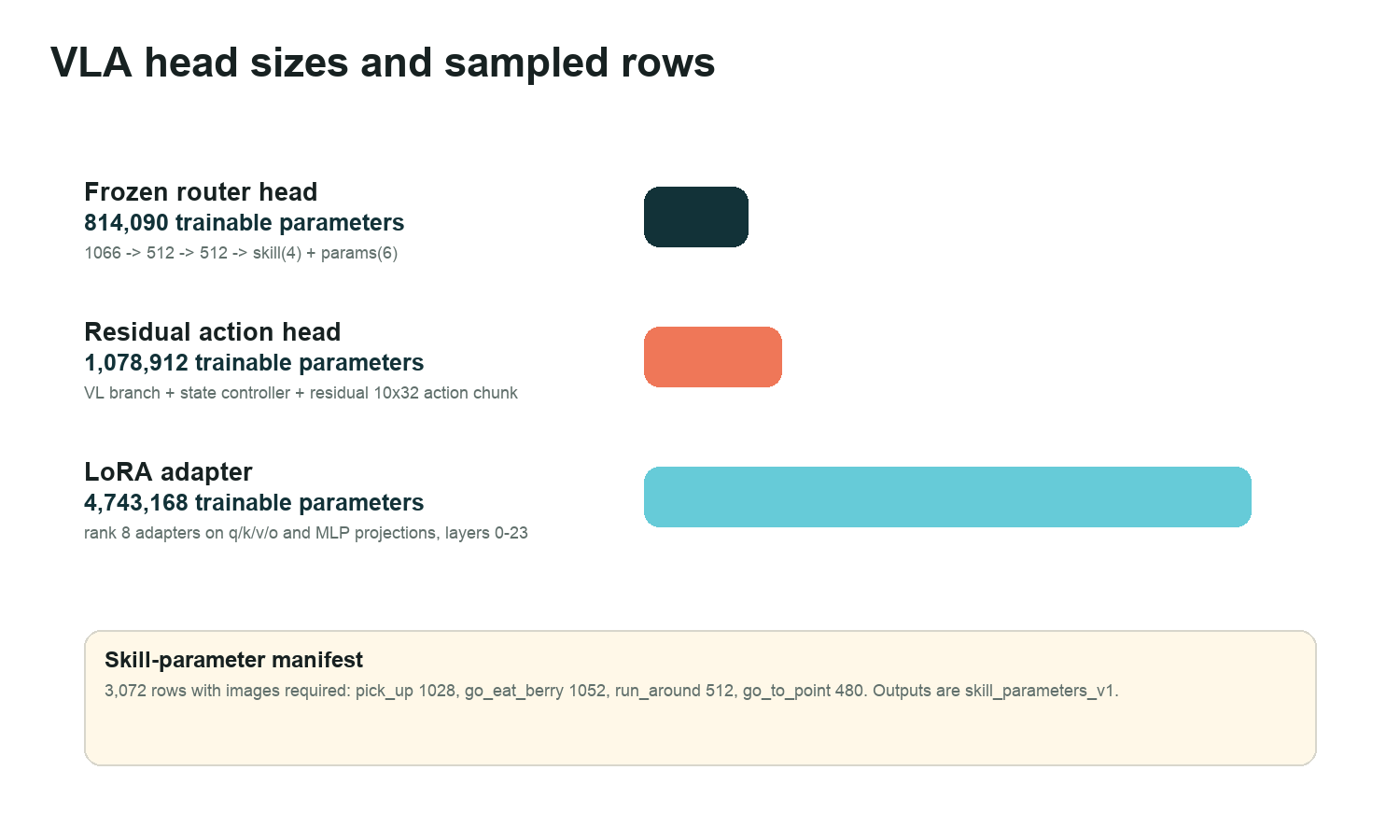
The promoted frozen router trains 814,090 head parameters. The residual 10x32 action-chunk head trains 1,078,912 parameters, while the LoRA adapter adds 4,743,168 trainable parameters across layers 0-23.
The dataset rows are image + state + command + action labels sampled from rollout frames, not isolated stills. Those same proof paths become the browser policy gallery and retarget evidence.
The technical path was deliberately staged: behavior cloning first, action chunks when one-step control failed, residual VLA heads for manipulation, then a safe router for the public demo.
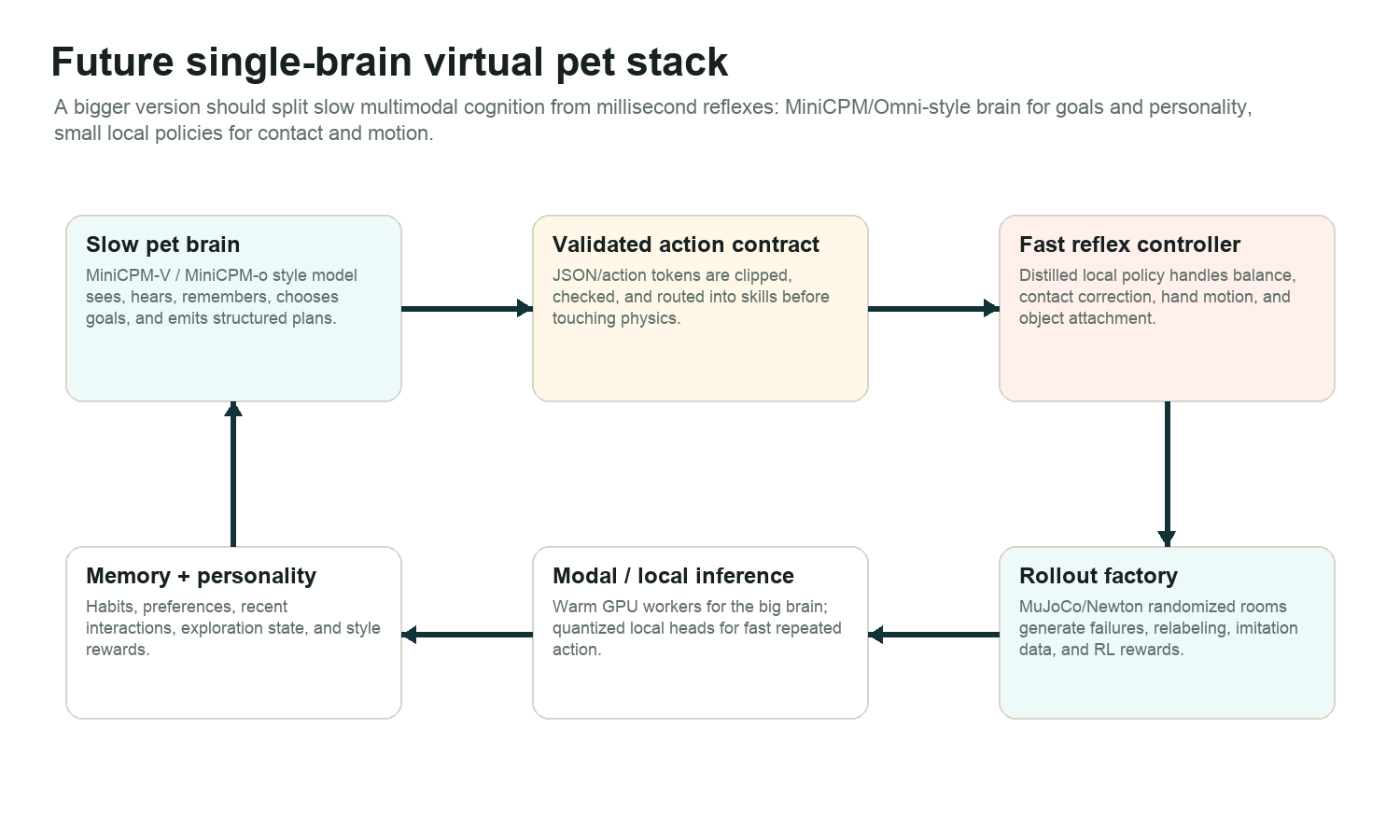
The larger version should separate a slow MiniCPM/Omni-style pet brain from a fast local reflex controller so the creature can feel alive without waiting on every model call.
The avatar pipeline is part of the model, not decoration. The SAM-cleaned Fire Boy body was repaired into a single connected mesh, bound to a humanoid skeleton, exported with motion clips, then compared against a MuJoCo body so simulator traces could drive the browser rig. The Fire Boy rig report records 3,311 vertices, zero unweighted vertices, and a clean single-component body for the shipped base.
The data pipeline is similarly explicit. The first four-skill manifest had 64 episodes and 2,368 image rows; the focused manipulation manifest expanded contact-heavy tasks to 144 episodes and 6,192 rows; the all-skill router manifest wrote 3,072 skill-parameter rows with images required.
# Sketch of the promoted VLA router
vl = MiniCPM_V_4_6(image, instruction).mean_pool() # 1024-d, frozen
state = build_robot_state(root, hands, mouth, targets, flags, previous_action) # 42-d
h = silu(linear(concat(vl, state), 1066, 512))
h = silu(linear(h, 512, 512))
skill_logits = linear(h, 512, 4)
params = linear(h, 512, 6) # target_xyz, radius, speed_hint, object_is_berry
loss = cross_entropy(skill_logits, skill_id) + 0.35 * mse(params, target_params)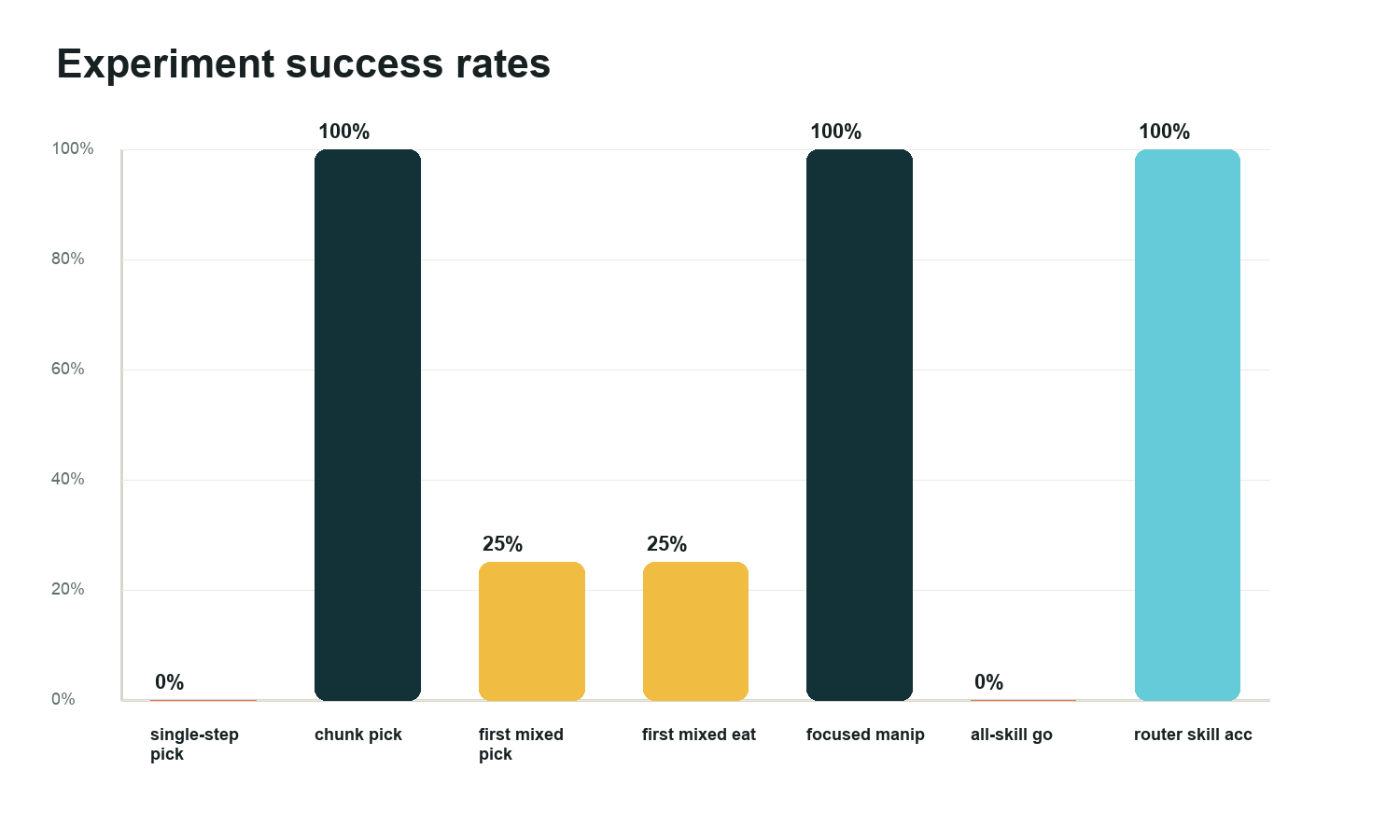
Single-step manipulation failed, chunked manipulation worked, the first mixed VLA dataset exposed data imbalance, and the final router solved the public-demo decision layer.
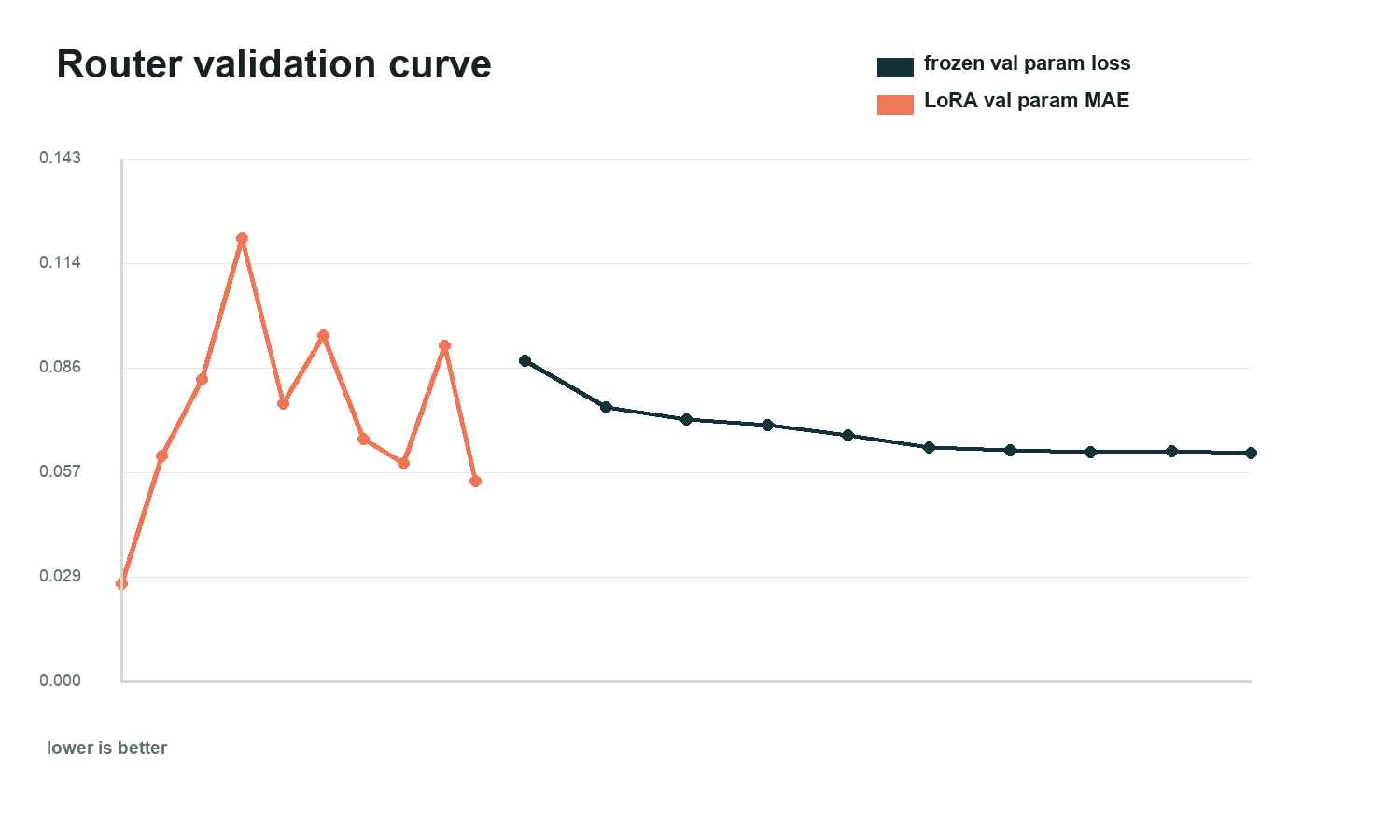
The frozen router kept perfect skill accuracy while validation parameter loss moved downward. LoRA preserved classification, but parameter precision was less stable.
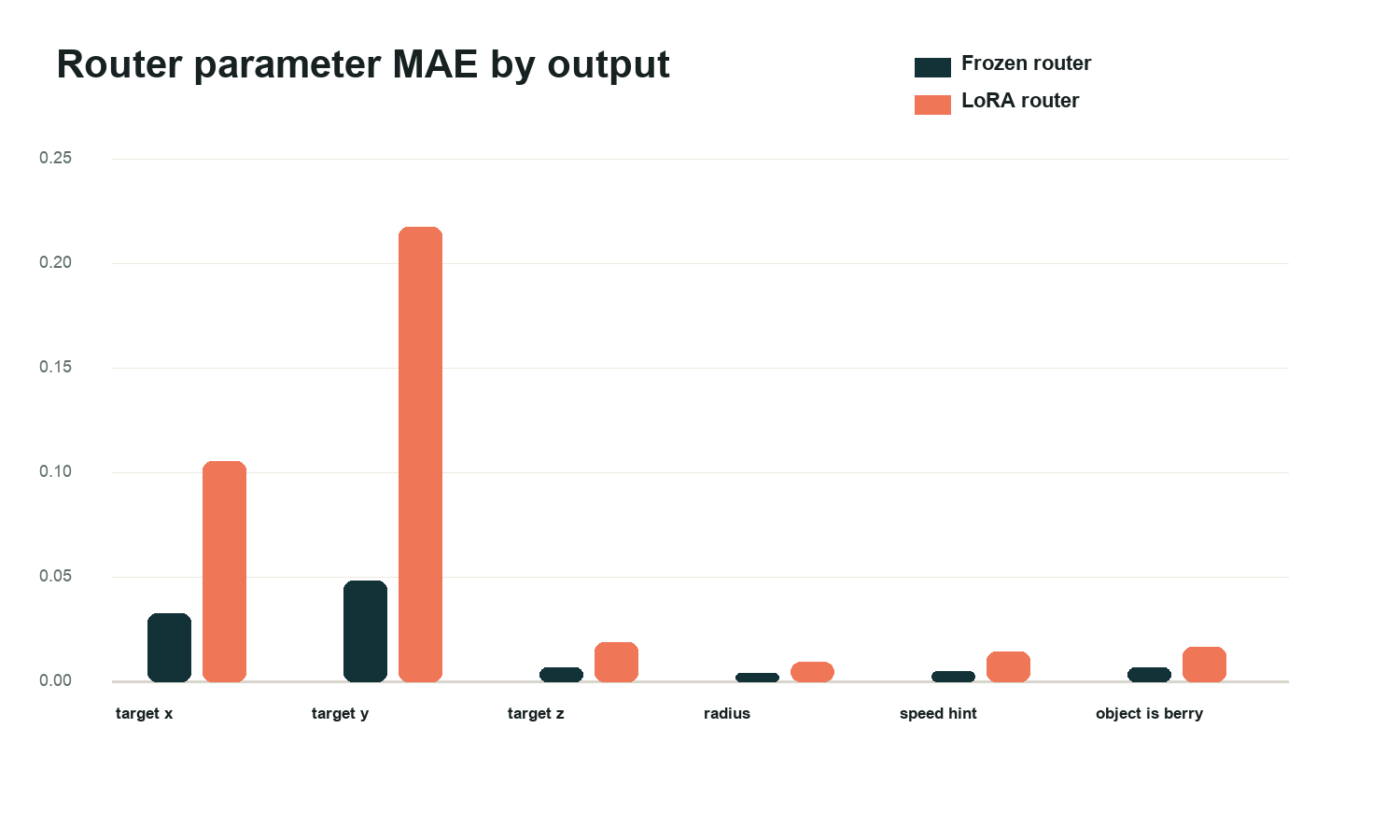
The LoRA router's biggest regression was coordinate precision, especially target_y. In physics, a small coordinate error becomes a visible miss.
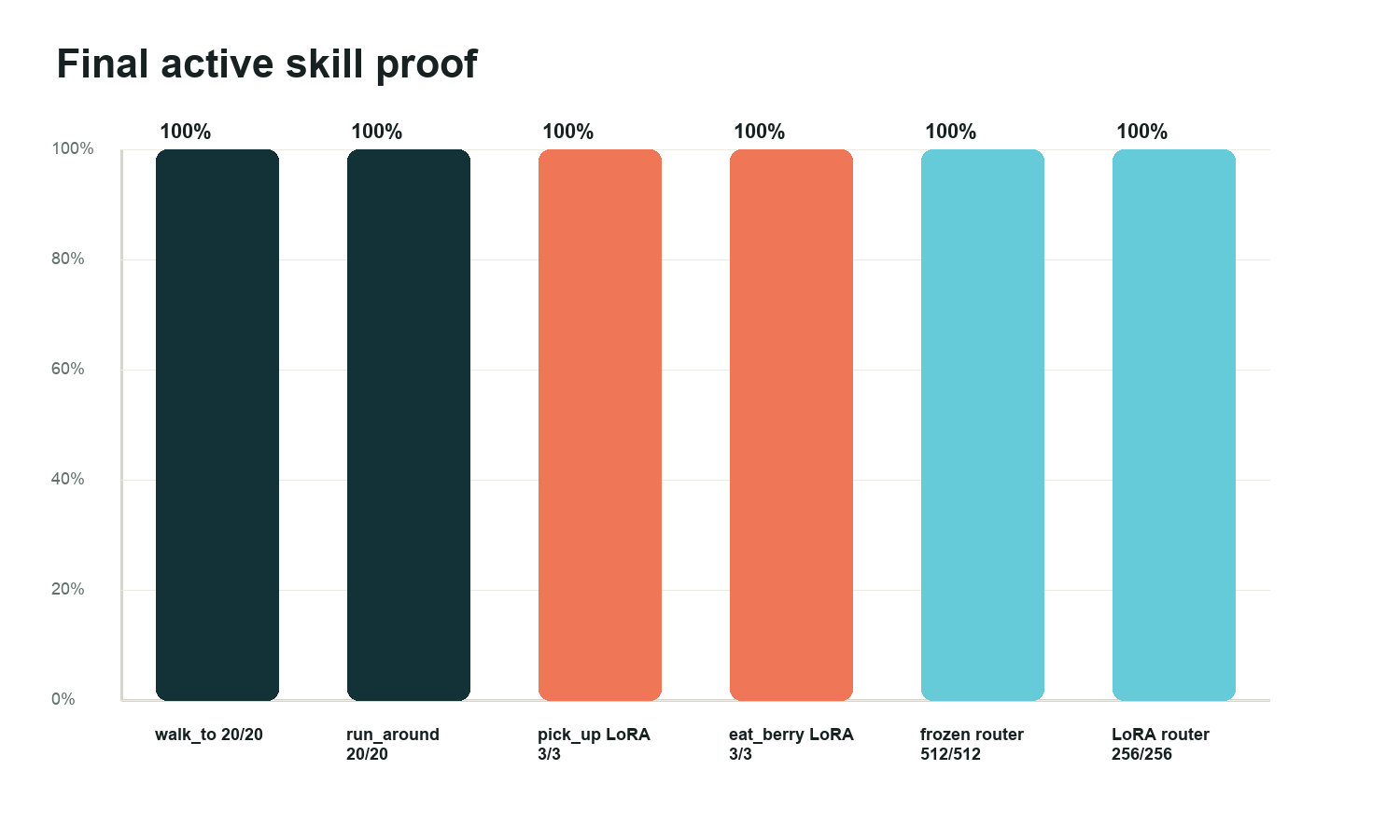
The demo stack combines proved skills: walk and run from MuJoCo articulated policies, manipulation from MiniCPM-V LoRA/residual proof lanes, and the frozen router for command selection.
| Part | Role in the VLA | Why it matters |
|---|---|---|
| Frozen MiniCPM-V 4.6 | Produces pooled vision-language hidden-state features from the image and instruction. | Protects the pretrained visual-language representation while the action interface is still being tested. |
| Robot state constructor | Builds navigation, object, hand, mouth, previous-action, task, stage, grasp, and eaten features. | Gives the model proprioception that cannot be trusted from pixels alone. |
| MLP trunk | Fuses the 1024-d MiniCPM-V embedding with the state vector through SiLU layers. | Keeps training fast and interpretable on RunPod GPUs. |
| Skill head | Predicts walk_to, run_around, pick_up, or find_and_eat_berry. | Maps language into a bounded action vocabulary with MP4 proof. |
| Parameter head | Predicts grounded target and behavior parameters. | Lets the same skill adapt to the ball, berry, viewer camera, or marker. |
| Stabilizers | Clip output ranges, copy explicit scene targets, and prefer heuristic skill for explicit commands unless forced neural. | Makes learned routing robust enough for a live demo. |
# Trainable sizes in the artifact
router_head = 814_090 # 1066 -> 512 -> 512 -> skill(4) + params(6)
residual_action_head = 1_078_912 # VL branch + state branch + 10x32 action chunk
lora_adapter = 4_743_168 # rank 8 adapters on q/k/v/o/gate/up/down, layers 0-23
# Router output contract
skills = ["walk_to", "run_around", "pick_up", "find_and_eat_berry"]
params = ["target_x", "target_y", "target_z", "radius", "speed_hint", "object_is_berry"]| Experiment | Result | Lesson |
|---|---|---|
| Single-step manipulation | pick_up 0/20, go_eat_berry 0/20 | One action target averaged across approach, reach, descend, close, lift, and mouth-transfer phases. |
| First mixed manifest | pick/eat 2/8 each, run 8/8, go_to 7/8 | The JSONL-to-head path worked, but contact-heavy data was too sparse. |
| All-skill direct low-level head | pick 2/2, run 2/2, eat 0/2, go_to 0/2 | A single low-level controller could not cover contact manipulation and locomotion reliably. |
| Direct go_to MiniCPM-V variants | 1-step, root-velocity, and recovery-root-velocity variants stayed at 0/5 | Closed-loop navigation exposed root drift and saturation that offline loss did not solve. |
| LoRA router promotion | perfect skill accuracy, but eval MAE 0.0629 vs frozen 0.0170 | Backbone adaptation was real, but the frozen router was numerically safer for the demo. |
MuJoCo is the proof source for the shipped policy gallery: eval JSON, MP4/GIF rollouts, body render checks, and Toy Room trajectory retargeting. The NVIDIA Newton lane is documented as the GPU physics scaling route: Fire Boy asset load test, CUDA rollout, qpos/action trace export, and MP4/USD/NPZ artifacts. The current public proof remains MuJoCo-backed, with Newton/Warp as the next simulation-throughput path.
The router rows pair a rendered observation with the instruction, a normalized robot-state vector, a skill id, and six grounded parameters. Contact tasks needed more data than navigation because pickup and eating pass through several phases: approach, reach above, descend, close, lift, transfer to mouth, and verify object state.
That is why direct one-step manipulation failed at 0/20, while chunked action policies reached 20/20. The final presentation keeps the router as the demo-safe VLA layer and treats low-level action heads as skill-specific research lanes until they pass broader randomized closed-loop tests.
| Dataset / head | Size | What it taught us |
|---|---|---|
| First four-skill manifest | 64 episodes, 2,368 image rows | The JSONL and image pipeline worked, but manipulation was underrepresented. |
| Focused manipulation manifest | 144 episodes, 6,192 rows | More contact-phase examples turned pick/eat from brittle into reliable eval behaviors. |
| Skill-parameter router manifest | 3,072 rows | Balanced high-level routing over pick_up, go_eat_berry, run_around, and go_to_point. |
| Frozen router head | 814,090 trainable parameters | Small enough to inspect and stable enough to promote for the live demo. |
| LoRA router adapter | 4,743,168 trainable parameters | Proved adaptation works, but coordinate MAE was worse than the frozen head in this run. |
The training loop started with behavior cloning because it gives a stable first signal: image, instruction, state, and the demonstrated action that solved the rollout. That worked for route selection and simple movement, but contact manipulation exposed the hard part of embodiment. A single next-action label averaged across approach, contact, lift, and mouth-transfer phases, so the controller looked reasonable offline but failed in closed-loop physics. The fix was to train short action chunks and then promote a skill-parameter router for the live demo.
| Stage | Training signal | Reason for keeping or changing it |
|---|---|---|
| Behavior cloning baseline | Rendered rollout image, language command, robot state, next action. | Fast, interpretable, and enough to prove the data path, but too phase-blind for manipulation. |
| Action chunks | 10-step x 32-actuator targets for contact-heavy pick/eat rollouts. | Preserved temporal phase, turning manipulation from 0/20 into 20/20 in the focused eval. |
| Residual VLA head | MiniCPM-V embedding plus state controller plus residual action branch. | Let vision-language features adjust the state policy without letting the whole controller drift. |
| Skill-parameter router | Four skill labels plus six continuous parameters. | Most robust public-demo layer: it routes to proved skills instead of asking one head to solve every motor regime. |
| Future RL layer | Task success, contact, smoothness, energy, time, curiosity, and personality rewards. | Useful only after the sim lane can generate enough rollouts and failures; otherwise RL optimizes brittle shortcuts. |
The current build uses a frozen MiniCPM-V encoder plus small action heads because that was the safest route for a hackathon demo. It is not the only way, and it is not the final most optimized form. A larger version should test multiple conversion strategies against the same closed-loop physics suite.
| Conversion method | What changes | When it is better |
|---|---|---|
| Frozen VLM + action head | Freeze MiniCPM-V, train only router/action MLPs. | Best first pass: cheap, stable, debuggable, and easy to run on modest GPUs. |
| LoRA / QLoRA adapter | Train low-rank adapters in the language/vision-language stack plus action heads. | Useful when the model must internalize action semantics, but it needs better numeric grounding checks. |
| Action-token fine-tuning | Represent skills, coordinates, or joint chunks as tokens and fine-tune the model to emit them. | Good for a single brain/controller interface, especially if the runtime can validate structured tokens. |
| Diffusion or flow action head | Generate action chunks as trajectories rather than single deterministic vectors. | Better for multimodal behavior where several actions are valid, such as playful motion or grasp approach. |
| World model + planner | Learn latent dynamics, predict future states, and plan before acting. | Better for long-horizon pet behavior, habits, curiosity, and multi-toy interactions. |
| RL after imitation | Start from behavior cloning, then improve in simulation using rewards. | Best once Newton/MuJoCo rollouts are fast enough to find many failures and recoveries. |
A future MiniCPM-V or MiniCPM-o style system could become the single high-level pet brain: see the toy room, understand speech, remember prior interactions, choose goals, select motor skills, and explain its own behavior. The fully fine-tuned route would train the model on multimodal episodes with observation frames, state summaries, action traces, rewards, and personality labels, then ask it to emit a structured action plan or compact action tokens.
The most practical architecture is still hierarchical. A slow brain handles language, personality, memory, and goal choice. A fast local policy handles millisecond reflexes: balance, hand motion, contact correction, and object attachment. Modal or another serverless GPU lane can run the slow multimodal brain, while a distilled local controller keeps the toy responsive.
| Layer | Latency target | Optimization path |
|---|---|---|
| Fast reflex policy | milliseconds | Distilled MLP/transformer head, quantized ONNX/WebGPU/WASM, cached state, no image model in the inner loop. |
| Skill router | tens of milliseconds when warm | Frozen MiniCPM features cached per frame, small head local or on a warm GPU worker. |
| Pet brain | sub-second to seconds | Modal warm containers, model weight cache, prompt/state compression, streaming responses, tool-call validation. |
| Training factory | offline | Run many MuJoCo/Newton rollouts, mine failures, relabel with success/failure, retrain adapters and skill heads. |
The build history shows a steady chain of OpenAI Codex-assisted work: shipping Toy Room v3, adding the Fire Boy command loop, wiring MiniCPM-V action paths, routing Toy Room v3 through Modal MiniCPM, adding brain trace diagnostics, hardening Modal WebSocket timeouts, keeping the MiniCPM-V loop live, making locomotion and pickup physical, grounding pickup targets, adding gestures, generating screenshots, and packaging this paper. The value was not a single magic patch; it was iteration speed with evidence discipline.
| Codex role | Concrete contribution |
|---|---|
| Scaffolding | Routes, frontend pages, training scripts, policy-gallery wiring, static assets, and local verification loops. |
| Experiment hygiene | JSON summaries, runbooks, artifact paths, screenshots, proof bundle validation, and paper/page generation. |
| Debugging | Modal timeout hardening, action contract validation, grounding fixes, retarget bridge checks, and browser QA. |
| Demo polish | Page directory, unique screenshots, PDF download/open controls, and a coherent narrative tying Modal, VLA, Newton, RunPod, and MiniCPM together. |
The current result is a practical VLA demo: MiniCPM-V sees the scene, the router grounds the command, and proof-backed policies make Fire Boy move, pick up, and eat in the Toy Room. The next research step is not a bigger page; it is broader closed-loop evidence with randomized objects, randomized rooms, longer tasks, and a Newton/Warp GPU rollout lane that can generate enough failures to train against.
| Reference | Why it is in the artifact |
|---|---|
| MiniCPM-V 4.6 model card | Backbone for frozen vision-language features and LoRA experiments. |
| Segment Anything | SAM-style segmentation is part of the avatar extraction and cleanup story. |
| MuJoCo | Simulator used for articulated body proof, closed-loop eval, and retarget traces. |
| NVIDIA Newton | Future GPU physics lane for scalable rollout generation and USD/MJCF-compatible traces. |
| Modal | Serverless GPU/runtime lane for the live MiniCPM-o action gateway. |
| OpenAI Codex | Agentic coding partner used throughout scaffolding, debugging, screenshot generation, and packaging. |
The embedded paper below is the generated PDF artifact. Use the buttons if the browser prefers opening PDFs in a separate viewer.